0. Presentation of the Course
Exams
100%, can use any notes including internet Take hop exam
Types of Questions
- Numerical Questions
- Theoretical questions
Difficulty Levels
- 60-80 marks: questions of the same type of those solved during the lectures
- 20-40 marks: questions that require some creativity and reasoning
Topics
Mainly about algebra and calculus
- Matrices
- Systems of Linear Equations
- Vector Spaces
- Linear Mappings
1. The Basics
Basic Definitions and notation
Set is a collection of items, name elements, characterised by a certain property Element belgons to indicated as Several elements of compose a subset
Want to inidcate all the elements of the set:
Want to say there exists(at least) one element of which has a certain property (such that):
Want to say there exists only/exactly one element of which has certain property
if statement 1 THEN statement 2
statement 1 IF AND ONLY IF statement 2
Cardinality of a set
coincident - every element of is also an element of and every element of is also an element of cardinality of a set is number of elements contained in empty - indicated with
Intersection and Union
intersection - - set containing all the elements that are both in the sets and union - - set containing all the elements that are either or both the sets and difference - - set containing all the elements that are in but not
Associativity of the Intersection
Numbers and Number sets
Set is finite if its cardinality is a finite number. Set is infinite if its cardinality is continuous if
Types of Number Sets
Continue from last semester ℂ - Set of number than can be expressed as where and the imaginary uni
Cartesian Product
New set generated by all the possible pairs
Relations
Order Relation
Indicated with if following properties are verified:
- reflexivity
- transitivity
- antisymmetry
Example
Let and let consider if and only if is a multiple of . More formally with
Equivalence
Indicated with if following properties are verified:
- Reflexivity -
- symmetry - then
- transitivity - and then
Equivalence Classes
Let be an equivalence relation defined on . The equivalence class of an element is a set defined as
Partition
Set of all the elements equivalent to is called equivalence class and is indicated with
Functions/Mapping
Relation is to be a mapping or function when it relates to any element of a set unique element of another. Let and be two sets, a mapping is a relation such that: (Every element, find only 1 element in other set such that y is = x)
The statement can be expressed also as Unary operator - Binary operator - or Internal composition law -
algebraic structure - set endowed with 1+ internal composition laws
Injective Functions
is injection if the function values of two different elements is always different: and if then Never crosses horizontal line twice. Doesnt cross it twice
Surjective Functions
is surjective if all elements of are mapped by an element of it follows that such that Graph has no holes. Y axis as got a function, eg crosses graph
Bijective Functions
is bijective when both injection and surjection are verified
Numeric Vector
Numeric Vector
- Let and
- Indicated with , set of ordered n-tuples of real numbers
- Generic element a = () is named numeric vector or simply vector of order n
Sum of Vectors
- Sum of vectors:
- Can also do the same for
Scalars
Numeric value is a scalar The product of a vector by a scalar is the vector Very similar to
Scalar Product
Generated by the sum of the products of each pair of corresponding components Example:
Properties
- Symmetry:
- Associativity:
- Distributivity:
Matrices
Matrix
2 natural numbers > 0. A matrix () is a generic table of the kind
where each matrix element
- m=rows, n=columns
- n order square matrix -
- rectangular -
Matrix Transpose
- Transpose matrix is whose elements are the same of A but
- Change index of row with index of columns (rotate it)
Symmetry
- Only on square matrix
- When
Diagonal and Trace
- Diagonal of a matrix is the ordered n-tuple that displays the same index twice. From 1 to
- Trace is the sum of the diagonal elements tr()
Null Matrices
- Is said null if all elements are zeros
Identity Matrices
- Square matrix whose diagonal elements are all ones while all the other extra-diagonal elements are zero
Matrix Operations: Sum and Product
Matrix Sum
Both matrices must be the same size! Can be subtracted from one another
Properties of the matrix sum
- commutativity:
- associativity:
- neutral element:
- opposite element:
Product of a scalar and a matrix
Matrix defined as: Similar to by the scalar
Properties of multiplying by a scalar
- associativity: and :
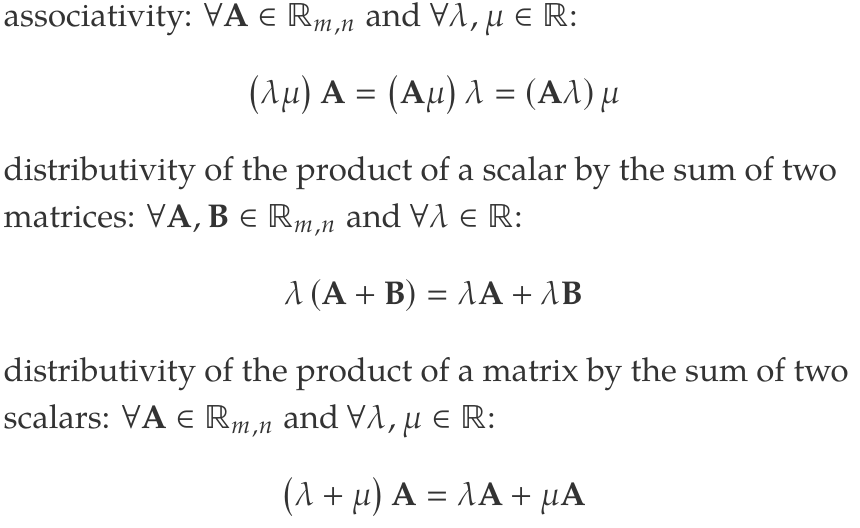
Matrix product
Product of matrices and is a matrix
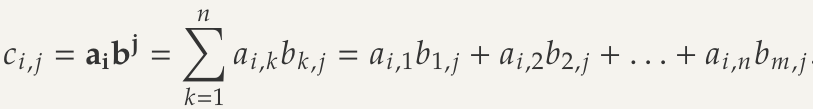
- Just the scalar product of row vectors of with column vectors of
- Number of columns in the first matrix must be the same as the number of rows in the second
- left distributivity:
- right distributivity:
- associativity:
- transpose of the product:
- neutral element:
- absorbing element:
Commutable - , one with respect to the other Every matrix is commutable with (and the result is always ) and with (and the result is always )
Determinant of a Matrix
(takes decades to understand)
- Most important concepts of maths
- Permutation: Different ways of grouping items, can be checked with factorials
- Fundamental Permutation - Reference a sequence
- Inversion - Every time two objects in a permutation follow each other in a reverse order with respect to the fundamental
- Even class permutation - Permutation undergone to an even number of inversions
- Also have Odd class permutation
Associated Product
Never in the same column/row. Product of this is referred to as associated product and is indicated with the symbol (c). Wont be the same number either.
Order the factors according to the row index:
![]()
Coefficient of nk
Consider 1-2-...-n as fundamental permutation, the scalar nk is defined as:

Determinant of a Matrix
indicated as det is the function
det:
defined as the sum of n! associated products:
 Do it as left to right diagonal +, then right to left diagonal as -
Do it as left to right diagonal +, then right to left diagonal as -
Linear Dependence/Independence
Linear Combination
If row can be represented by other rows with weighted sum by means of the same scalars
Linear dependence
If null vector can be expressed as the linear combination of the rows ( columns) by means of nun-null scalars Rows are linearly dependent if
such that
![]()
Linear Independence
If only way to express a row of all zeros as the linear combination of the m rows(n columns) is by means of null scalars
Fundamental property of Linear Dependence
r rows are linearly dependent if and only if at least one row can be expressed as the linear combination of the others
Properties of determinants
Determinant of a matrix is equal to the determinant of its transpose matrix
- Transpose Matrix:
- Triangular Matrix: Equal to the product of the diagonal elements
- Row(Column) swap: If two rows (columns) are swapped the determinant of the matrix is
- Null determinant: if two rows(columns) are identical(sum) then
- If and only if the rows(columns) are linearly dependent
- if and only if at least one row(column) is a linear combination of the other rows(columns)
- if a row(column) is proportional to another row(column)
- Invariant Determinant: Row(column) the elements of another row(column) all multiplied by the same scalar are added, the determinant remains the same
- Row(column) multiplied by a scalar: Row(column) is multiplied by then
- Matrix multiplied by a scalar: If is scalar,
- Determinant of the product: Product between two matrices is equal to the products of the determinants.
Adjugate Matrices
Submatrix
Obtained from by cancelling rows and columns. Where r,s 2 positive integers such that and
- Rows dont have to be continuous
- Can be obtained by cancelling the second row, second and fourth column
- Minor: Determinant of submatrix
- Major: If submatrix is the largest square
- Complement submatrices: Obtained by cancelling on the row and the column from to the element
- Complement Minor: Determinant, indicated
- Cofactors:
Adjugate Matrix
Let be the cofactor for . The adjugate matrix (adjunct or adjoin) is:
Dan Terms: Transpose it (Flip i,j around), then calculate the determinate of the remaining rows once removed it(the sub matrix, as would do normally). Then alternate between 1 and -1.(Use cofactors formula!. )
Tutorial Def:
- All Compliment miners
- Multiple by coefficent = adjudigate matrix
Laplace Theorems
Theorem 1
Determinant of can be computed as the sum of each row(column) multiplied by the corresponding cofactor for any arbitrary for any arbitrary
The determinant of a one-element matrix is just the element , can compute the determinant of any square number
Theorem 2
Sum of the elements of a row(column) multiplied by the corresponding cofactor related to another row(column) is always zero for any arbitrary for any arbitrary
minors are the row you remove, so you take sub matrix of the remaining part. = minor
Introduction to Matrix inversion
Inverting a matrix
For a square matrix, , the inverse is which is define as the matrix for which
- Invertible Matrices: a matrix
- Unique Inverse a matrix
- Inverse matrix :
- Singular/Non Invertable/ Linear Dependent:
- Non-singular:
- Inverse of a matrix product:
Orthogonal Matrices
is said orthogonal if the product between it and its transpose is the identity matrix:
An orthogonal matrix is always non-singular and its determinant is either 1 or -1
A matrix is orthogonal if and only if the ssum of the squares of the element of a row(column) is equal to 1 and the scalar product of any two arbitary rows(columns) is equal to 0:
Rank of a Matrix
Rank - of matrix , indicated as is the highest order of the non-singular submatrix . So max value of rank in 3x3 matrices would be 3. If there is linear independence, then go to 2x2 and so forth. If is the null matrix then its rank is taken equal to 0
Matrix has ρ linearly independent rows(columns).
Rank is c
Sylvester's Lemma
and . Let be non-singular and be the rank of the matrix . Follows that the rank of the product matrix is
Law of Nullity
follows from the previous lemma and be the ranks and be rank of the product AB. FOllows that:
Systems of Linear Equations
Basically simultaneous equations. Can be written as
The coefficient matrix is said incomplete matrix. The matrix whose first columns are those of the matrix and the column is the vector is said complete matrix
Cramer's Theorem
If is non-singular , the is only one solution simultaneously satisfying all the equations: if then such that
Hybrid Matrix
Hybrid matrix with respect to the column is the matrix obtained from by substituting the column with (Switch with )
Cramer's Method
For a given system of linear equations with non-singular, a generic solution element of can be computed as
For a square matrices would repeat 3 times, change column 3 times with
Rouchè-Capelli Theorem
Solutions for systems of linear equations
- compatible if it has at least one solution
- determined if it has only one solution
- undetermined if it has infinite solutions
- incompatible if it has no solutions. Has a split
Theorem
is compatible if and only if both the complete and incomplete matrices () are characterised by the same rank named rank of the system
Cases
- Incompatible, no solutions - system is compatible. Under these conditions, three cases can be identified:
- - System is a Cramers system and can be solved Cramers method
- equations of the system compose a Cramers system. The remaining are linear combination of the other, these equations are redundant and only 1 solution
- is undetermined and has
How to choose the equations to cancel?
- Cannot cancel any equations
- Need to ensure that the cancellation of an equation does not change the rank of the incomplete matrix
- Have to cancel only linearly dependent equations, that is rows of the matrix
General Solutions of Undetermined Systems
- Select the rows linearly independent rows of the complete matrix
- Choose (arbitrarily) variables and replace them with parameters
- Solve the system of linear equations with respect to the remaining variables
- Express the parametric vector as a sum of vectors, where each parameter appears in only one vector
Homogeneous Systems of Linear Equations
Homogeneous if the vector of known terms is composed for only zeros and is indicated with O. Solution of at least null vector
General solution of a system
If a solution of the homogeneous system then is also a solution to the system
Combination of solutions
If and are both solutions then every linear combination of these two n-tuple is solution of the system.
Special Property
Homogeneous system of equations in variables. System has solutions proportionate to the n-tuple
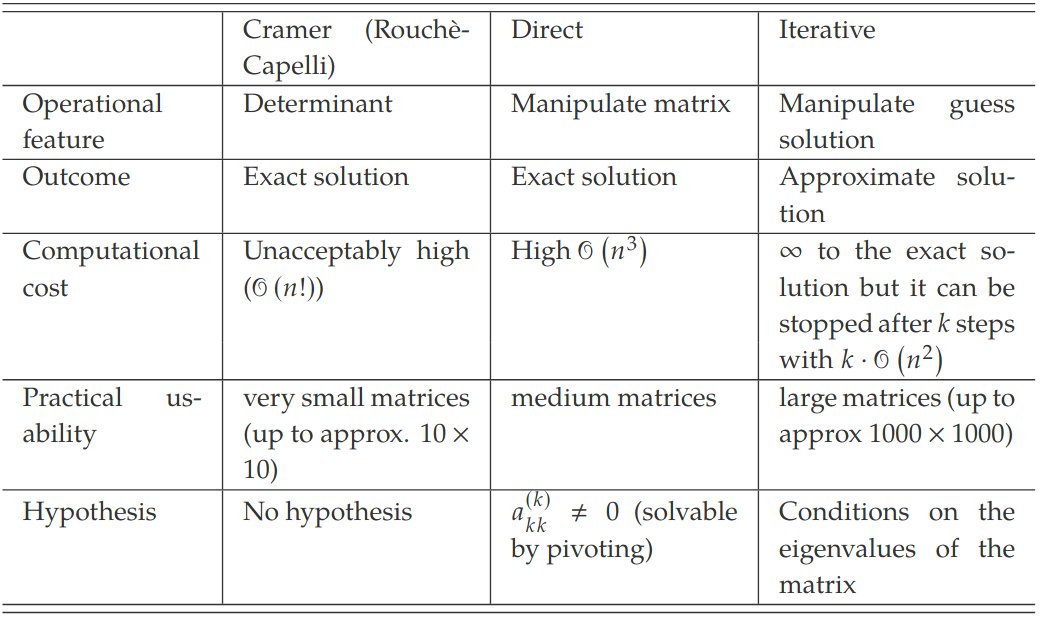
- Cramers Method requires the calculation of 1 determinant of a order matrix and determinate of order matrices
- Means elementary operations
- Need to find alternative methods as takes too long
Theoretical Foundations of Direct Methods
Elementary Row Operations
- : Swap of two rows and
- : Multiplication of a row by a scalar
- : Substitution of a row by the sum of the row to another row :
Equivalent Matrices and Equivalent Systems
Equivalent Matrices: Apply the elementary row operations on , obtain new matrix .
Equivalent Systems: 2 systems of linear equations in the same variables: and . These two systems are equivalent if they have the same solutions
Consider a system of linear equations in variables . Let be the complete matrix associated with this system. If another system of linear equations is associated with a complete matrix equivalent to , then the two systems are equivalent
- : The swap of two rows, the equations of the system are swapped, no effect on the solution of the system
- : Same solutions, modified systems is equivalent to the original one
- : After operation, the modified system is equivalent in solutions to the original one
Direct Methods
Direct methods are methods for solving systems of linear equations by manipulating the original matrix to produce an equivalent system that can be easily solved. A typical manipulation is the transformation of a system of linear equation into triangular system
Gaussian Elimination
- Construct the complete matrix
- Apply the elementary row operations to obtain a staircase complete matrix and triangular incomplete matrix, that is we add rows to obtain a null element in the desired position
- Write down the new system of linear equations
- Solve the equations of the system and use the result to solve the
- Continue recursively until the first equation
To obtain the matrix would do: As it keeps going on, it gets longer and longer, to create a matrices with leading zeros
Dan Method: This completes the first 2 rows and first column. Then have to increase m, to do second column
LU factorisation
Direct method that transforms a Matrix into a matrix product where is a lower triangular matrix having the diagonal elements all equal to 1 and is an upper triangular matrix Pose solve at first the triangular system and then extract from the triangular system Does not alter the vector of known terms .
If working with non singular matrix, then split any matrix into a product such that . If non-singular matrix and is square, and has det of 0, then lower traingular matrix having all the diagonal elements equal to 1 and upper triangular matrix such that
Equivalence of Gaussian elimination and LU factorisation
- Gaussian elimination and LU factorisation are both direct methods
- They are not identical but they are equivalent
- Whilst performing the algorithm the LU factorisation is implicitly performed
- Both Gaussian elimination and LU factorisation have a lower complexity than theoretical methods
- The complexity is in the order of operations
Short introduction to Iterative Methods
Jacobi's Method - Starts from an initial guess , iteratively apply some formulas to detect the solution of the system.
Unlike direct methods that converge to the theoretical solution in a finite time, iterative methods are approximate since they converge, under some conditions
Definition of Vector Space
Vector Space
- to be a non-null set and to be a scalar set
- Vectors: elements of the set
- - Internal composition law,
- - External composition law,
- () is said vector space of the vector set over the scalar field () if and olf if the ten vector space axioms are verified
Axioms
- is closed with respect to the internal composition law:
- is closed with respect to the external composition law:
- Commutativity for the internal composition law:
- Associativity for the internal composition law:
- Neutral element for the internal composition law:
- Opposite element for the internal composition law:
- Associativity for the external composition law: and
- Distributivity 1: and
- Distributivity 2:
- Neutral elements for the external composition law:
Vector Subspace
() be a vector space, and The triple () is a vector subspace of () if () is a vector space over the same field with respect to both the composition laws
Proposition shows that we do not need to prove all 10 axioms, just need to prove closure of the two composition laws.
Null vector in Vector Spaces
() be a vector space over a field . Every vector subspace () of () contains the null vector. For every vector space (), at least two vector subspace exist
Intersection and Sum Spaces
Intersection Spaces
If () and () are two vector subspace of (), then () is a vector subspace of ()
Sum Space
() and () be a vector space of (). Sum subset is a set defined as
Direct Sum
() and () be two vector subspaces of (). If the subset sum is indicated as and named subset direct sum
Linear dependence in dimensions
Basic Definition
- Linear combination of the vectors by means of scalars is the vector
- Said to be linear dependent if the null vector o can be expressed as linear combination by means of the scalars
- Vectors are linearly independent if the null vector can be expressed as linear combination only by means of the scalars
- Are linearly dependent if and only if at least one of them can be expressed as linear combination of the others
- Would then check them as you would do in matrices
Linear Span
Set containing the totality of all the possibly linear combinations of the vectors, by means of scalars.
Properties
- Span with the composition laws in a vector subspace of ()
- with . If vectors are linearly independent while each of the remaing vectors is linear combination of the linearly independent vectors, then
Basis of a Vector Space
Basis
Vector space is said to be finite-dimensional if a finite number of vectors such that the vector space where the span is .
A basis of is a set of vectors that verify the following properties:
- They are linearly independent
- They span , i.e.
Null Vector and Linear Dependence
If one of the vectors is equal to the null vector, then these vectors are linear dependent
Steinitz Lemma
= Finite-dimensional vector space = E its span Let be linearly independent vectors Follows that , the number of a set of linearly independent vectors cannot be higher than the number of vectors spanning the vector space.
Corollary of the Steinitz Lemma
^continuation be its basis, it follows that . The vectors composing the basis are linearly independent. For the Steinitzs Lemma, it follows immediately that
Dimension of a Basis
Order of a Basis
Number of vectors composing a basis is said order of a basis All the bases of a vector spaces have the same order
Dimension of a Vector Space
The order of a basis is said dimension is indicated with dim or dim(). The dimension dim of a vector space is:
- the maximum number of linearly independent vectors of E
- the minimum number of vectors spanning E
Linear independence and dimension
The vectors span the vectors if and only if they are linearly independent
Grassmann Formula
Reduction and Extension of a basis
Basis Reduction Theorem - If some vectors are removed a basis of is obtained Basis Extension Theorem - Let be linearly independent vectors of the vector space. If are not already a basis, they can be extended to a basis (by adding other linearly independent vectors)
Unique Representation
If the vectors are linearly dependent while is linearly independent, there is a unique way to express one vectors as linear combination of others (How you would represent other lines with one another, identify them with lambdas)
Grassmanns Formula
Let and be vector subspace of . Then,
Basic Definitions of Mappings
Mapping and Domain
be a set such that The relation is said mapping when Said domain and is indicated with
A vector such that is said to be the mapped (or transformed) of through
Image
Image () is a set of all all vectors that exist such that
dom/domain = Input Image = output also means a subset
Surjective, injective, bijective
Mapping is surjective if the image of coincides with
Mapping is injective if with (if is different from , then so will )
Mapping is bijective if is injective and surjective
Linear Mappings
Linear Mapping
Linear mapping if the following properties are valid:
- Additivity:
- Homogeneity: and
(This happens very very rarely)
Affine Mapping
Said affine if $ g(v) = f(v) - f(u)$ is linear
Linear Mappings
Image of through , is the set Follows that the triple is a vectors subspace of
Inverse Image
The inverse image of through , indicated with is a set defined as:
Matrix Representation
Linear mapping can be expressed as the product of a matrix by a vector
Image from a matrix
The mapping is expressed as a matrix equation . Follows that the image of the mapping is spanned by the column vectors of the matrix A: where
(Just convert matrix into (A). Columns into own (C))
Endomorphisms and Kernel
Endomorphism
. If , then linear mapping is endomorphism
Null Mapping
is a mapping defined as
Identity Mapping
(Should be same dimension) is a mapping defined as
Matrix Representation
be endomorphism. Mapping of multiplication of a square matrix by a vector:
. The inverse function
Linear dependence
Needs to be endomorphism likely dependent then so are
Kernal
linear mapping
Kernal as Vector Space
The triple is a vector subspace of
Kernal and Injection
be a linear mapping . Follows that if and only if
Theorem
Mapping is injective if and only if:
Linear Independence and injection
be linearly independent vectors . If is injective then are also linearly independent vectors of Endomorphism is invertible if and only if it is injective
Rank-Nullity Theorem
Let be a linear mapping. The rank of is the dimension of the image, The rank is an invariant of the map.
The dimension of the kernel, is said nullity of a mapping.
Theorem
Under the hypothese: the sum of rank and nullity of a mapping is equal to the dimension of the vector space : Usually is the hardest to calculate and this theorem allows an easy way to compute it as
Proof
If then is injective. If the basis spans the image, the vectors are linearly independent.
Corollaries of Rank-Nullity Theorem
Let be an endomorphism where is a finite-dimensional vector space.
- If is injective then it is also surjective
- if is surjective then it is also injective
Corollary
Let be a linear mapping with and .
- Consider . Follows that the mapping is not injective.
- Consider . Follows that the mapping is not surjective
Eigenvalues and Eigenvectors
Let be an endomorphism where is a vectors space with dimension . Every vector such that with a scalar and is said eigenvector of the endomorphism related to the eigenvalue Eigenvalue and eigenvector are building blocks of reality
Dan terms: = eigenvalue (num of x) = eigenvector (any number) homogeneous = (0,0)
Eigenspace
Let be an endomorphism The set with defined as This is said eigenspace of the endomorphism related to the eigenvalue . The dimension of the eigenspace is said geometric multiplicity of the eigne value and is indicated with
Determining Eigenvalues and Eigenvectors
Let be an endomorphism. Let be the order characteristic polynomial related to the endomorphism. The number of roots of is called algebraic multiplicity.
Introduction to Diagonalization
One variable for each line in a diagonal manner. Not all the mappings/matrices can be diagonalized, Need to have enough linearly independent columns of .
Let be an endomorphism. The matrix is diagonalizable if and only if it has n linearly independent eigenvectors:
- All the eigenvalues are distinct
- The algebraic multiplicity of each eigenvalue coincides with its geometric multiplicity
Symmetric Mappings
If the mapping is characterised by a symmetric matrix, then can prove that;
- The mapping is always diagonalisable
- The transformation matrix can be built to be orthogonal (. Also means the new reference system given by the eigenvectors is also a convenient orthogonal system