26. Exam Practise Questions
Lecture 10
- Mutexes in some operating systems will put the tread to sleep after it has been spinning for a while? why?
- Does one need mututal exclusion when using user threads?
- Does the implementation with counting semaphores work for a single producer and single consumer (bounded/unbounded)
Lecture 11
Can I initialise the value of the
eatingsemaphore to 2 to create maximum parallelism
- Would it deadlock?
- Do we get maximum parallelism?
Lecture 14
Compare the storage needed to keep track of free memory using bitmap vs. linked list with a main memory of 8 gygabytes, and a block size of 1 megabyte. For the linked list, assume that exactly half of the memory is in use, and that memory contains an alternating sequence of occupied blocks and free blocks. We will only keep track of free blocks with this list, assuming that each node needs a 32-bit memory address, a 16-bit length, and a 16-bit next-node field.
- How many bytes of storage are required for each method?
Lecture 15
Given a 64-bit machine that uses paging, and a page/frame size of 4096 bytes
What would be the maximum number of frames? Hint: First compute the maximum number of bytes you can address with a 64-bit machine
How many pages do we have in a 17 kilobytes process? How much memory are we wasting in the last partition?
Lecture 16
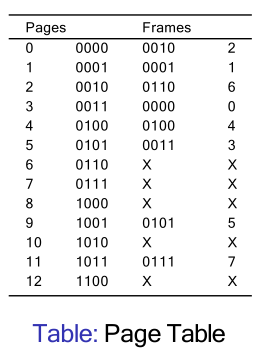
- Given a 4KB page/frame size, and a 16-bit address space, calculate:
- Number M of bits for offset within a page.
- Number N of bits for representing pages. So, number of pages?
- What is the physical address for 0, 8192, 20500 using this page table?
Lecture 17
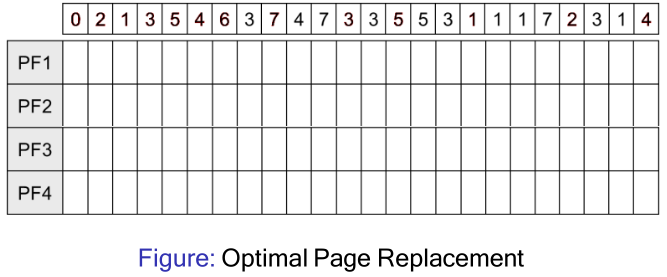
- Compare FIFO with the optimal page replacement algorithm. The process starts up with none of its pages in memory.
- What would be the minimum number of page faults that would be generated by the optimal approach?
Hard Disk Example Questions



Lecture 19
Disk requests come in to the disk driver for cylinders 10, 22, 20, 2, 40, 6 and 38, in that order. A seek takes 6ms per cylinder.
- How much seek time is needed for: FCFS, SSTF and Look-SCAN (initially moving upward)
- In all cases, the arm is initially at cylinder 20.
Lecture 21
We have seen that with i-nodes, the maximum file size that we can have depends on the block size and the number of indirections.
- Assuming a 32-bit disk address space, what would be the maximum (theoretical) file size for the FAT file system with a drive of 500GB and a block size of 1KB? (without accounting for directory metadata)
- The most used implementation of FAT is known as FAT-32. Investigate why there is a theoretical limitation of 4GB per file (and sometimes even less than 2GB).
Lecture 22
Following up the previous question on FAT-32, we mentioned that FAT-32 has severe limitations (e.g. the file allocation table could be too big).
- Why do you think that this file system is still in use in most of flash drives, cameras or MP3 players?
- When would you consider formatting your flash drive with NTFS or ext3?
- If you format your flash drive with (Windows) NTFS, will it work (directly) in Unix systems?
Lecture 23
Exercise 1: Using the ext2 file system (i.e. 12 direct block addresses are contained in the i-node, and up to triple indirect), and assuming a block size of 4 kilobytes, and a 32-bits disk address space.
- Could we store a file of 18 gigabytes?
- How many disk blocks we spend for the i-node of a file of 16 megabytes? Exercise 2: In Linux, how many lookups are necessary to find (and load) the file: /opt/spark/bin/spark-shell?
Ex 1 a
! We have blocks of 4 kilobytes, and we need 32 bits (4 bytes) to represent a disk address ⇒ in one single block, we could store up to 1024 block pointers: 4KB = 4210 / 4 bytes each = 210 = 1024 block pointers. Using the 12 direct block pointers, we could have a file of with 12 blocks. Using the single indirect: 1024 extra block pointers. Using the double indirect: 10241024 block pointers (1048576). Using the triple indirect, 102410241024 block pointers (1073741824). If we aggregate all of them => 1,074,791,436 blocks of 4KBs which is approx 4TB
Ex 1 a
For a file of 16 megabytes, we need: 16220/4210 = 212 = 4096 blocks pointers! We will use fully all direct block pointers (12) [1 block] With the single indirect we have 1024 extra block pointers [1 block] With the double indirect we can address 1048576 block pointer... so we won’t go further than this level. With direct pointer and single indirect we have covered 1024+12 block pointers... we still need 3060 Each block will handle 1024 pointers. So, 3060/1024 = 2.9882 We need three blocks + the “first level” block. Total: 6 blocks of 4 kilobytes => 24KB

Lecture 24
- Why do type 2 hypervisors exist? After all, there is nothing they can do that type 1 hypervisors cannot do and the type 1 hypervisors are generally more efficient as well.
- Can a virtualised OS (e.g. Cent OS 7) use a paging system with virtual memory to manage its own memory? If yes, will this be using TLBs?
Exam Paper
Question 1
a.
New - Process has just began and waiting to be admitted. -> ready, when to admit process to the system Ready - process is waiting for the cpu to become available. -> running, decide which process to run next Running - process owns the CPU -> ready, when to interrupt process, -> Blocked, waiting for io, -> exit, finished executing Blocked - process cannot continue, could be waiting for IO -> ready, when process has finished waiting/can continue Exit - Process is no longer executable
b.
Necessary for context switching in multi-programmed systems. Changes the state of the current process, either from running, ready, suspended etc. Would expect it to handle interrupts, and multi tasking, ensuring one process is not hogging the CPU. This cannot be accessed directly, more so through system calls, at user level, so it cant be abused or cause issues within the os. Only kernel mode can access it.
c.
d.
Kernel level threads will be quicker as that can achieve true parallelism, unlike user level which cannot. With user level, once it becomes deadlock, the entire process is. With kernel level, if one gets deadlock, the others can still run, and the workload can be divided between them.
e.
You would get 3 childs because the child process still executes the forloop. This can be fixed by having an exit or break statement in the child condition where else if(pid==0)
f.
i.
Priority Queue - Process C, complete (15) Process D, wait 15, 15, 5, complete (35) Process B, wait 35, 15, wait 15, 15, wait 15, 5 (100) Process A, wait 50, 15, wait 15, 15, wait 5, 15, 5 (120) Shortest Job First Queue C,D,B,A
ii.
Avg response: 25ms
iii.
Avg turnaround: 68ms
Question 2
a.
- Mono-programming + process always allocated the entire memory space - has direct access to physical memory, which means OS
- Fixed partitions with equal size + reduces internal fragmentation - result into starvation
- Dynamic Partitions + processes are allocated the exact amount of contiguous memory it requires - external fragmentation
- Paging + no external fragmentation - bigger it gets, the slower it gets
- Virtual memory with paging + all pages loaded into memory which reduces page fault rates - ?
b.
Mutual exclusion - only one process can be in its critical section at one time Progress - any process must be able to enter its critical section at some point in time Fairness/bounded waiting - fairly distributed waiting times, cannot wait indefinitely.
c.
Best would be a mutex as they are more efficient than a semaphore on a multi-core machine. Furthermore the mutex and be implemented like a semaphore. With a normal semaphore, a thread can experience starvation/deadlocks depending on the implementation of the system due to poor LIFO.
d.
i. High priority process can wait for a resource which is held by a lower priority process ii. ? iii. ? iv. ?
e.
The output printed will be 0, due each child having a local/individual version of the iCounter. Only the parent process outputs the iCounter, and due to it not changing, It'll still be 0.
f.
?
Question 3
a.
When program is first run, wont know in advance which partitions/addresses it will occupy. Program addresses should be relative to where the process has been located. Is important nowadays due to multi-core/threading systems dynamically switch between programs, its necessary to relocate objects. ??
b.
Mutual exclusion - resource assigned to one process Hold and wait condition - held whilst requesting new resource No preemption - resource cannot be forcefully taken away from a process Circular wait - circular chain of process waiting for a resource held by another resource. ???
c.
??
d.
e.
Not on spec
f.
first fit - b, a, e next fit - b,c, e or rest of c and d best fit - b, f, e
Question 4
a.
Thrashing is when pages are swapped out and loaded again immediately. Possible causes are when the degree of multi-programming is too high. Can be prevented by good page replacement policies or by adding more memory.
b
Contiguous + Simple to implement, only location of first block and length is required. - Exact size of file beforehand is not always known Linked list + file sizes can grow dynamically, new blocks can be added to the end of the file - Space is lost within the blocks due to the pointer Fat + no space is lost due to the pointer - size of the allocation table grows with the number of blocks i-nodes + greatly increases disk performance on writes, file creates etc - Not been widely used because it is highly incompatible with existing file systems
c.
Ext3/4 implement journaling. It also allowed for increased filenames and sizes, which improved directory implementation. They are also a lot more reliable compared to i-nodes as it would reduce fragmentation by storing i-nodes, files and parent directories in the same block group if possible. Also meant it was quicker to access.
d.
yet to lean
e.
f.
g.
230