16. Distribution & Replication
05/05/23
Approach
- Assume that processes can be trusted, there are no arbitrary failures and communication is reliable
- Set aside a specialised coordinator process to coordinate the entire transaction
Algorithm Overview
- Each participant breaks down the operation into two stages or phases
- Tentatively performing the operation
- Making the successful result permanent and visible (committing the result)
- These two stages or phases are managed by the coordinator process
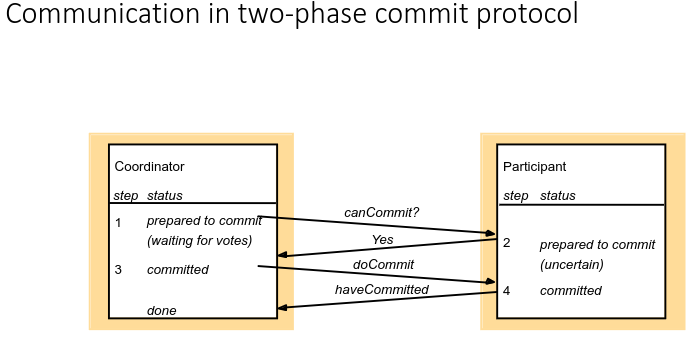
The two=phase commit protocol
.....
Notes
- So if no operation fails then all processes will reply to canCommit? with Yes
- All of the operations will be committed
- Effects of all operations will be observed
- So if any operation fails then the process will reply to canCommit? with No
- All of the operations will be aborted
- So no effect of any operation will be observed
Failures
- But what will happen if a process crashes??
- Depends when:
- Before any doCommit the transaction can be aborted,
- but afterwards it cannot
- Need to be sure in that case that the process will be restarted and will definitely commit the operation
Data Replication
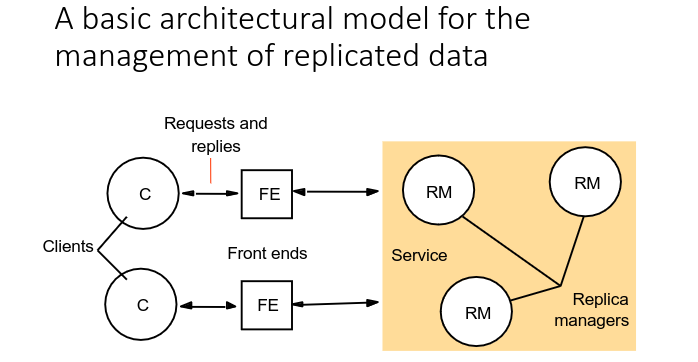
(A) System model for managing replicated data
- We will assume physical replicas of objects are maintained by Replica Managers (RMs)
- A service is provided by a cooperating set of RMs
- Each client (only) makes requests via a Front End
- May be part of the client, or may be a separate process
- Provides the basis for client replication transparency
- Requests can be read-only or update
Phases of request handling (general framework)
- Request issued by FE (Either to one RM or multicast to all RMs)
- Coordination between RMs on whether to perfrom request and in what order
- Typically FIFO, or may be Casual or Total order
- Execution by RMs
- Agreement by RMs on effect
- Response by one or more RMs to FE
Fault tolerant service
- Want to use this model to design a fault tolerant service which can tolerate up to f process failures
- (Intuitively) correct if each client gets the same results as they would have got from a single correct Replica Manager
Option 1 - Passive (primary backup) replication request handling
- Request - (with unique ID) is sent by the clients Front End to one primary Replica Manager
- Coordination - The primary takes requests in order
- Execution - The primary executes a stores results
- Agreement - If request is an update, the primary sends updated state, response and ID to all backup RMs
- Response - Primary responds to FE and hence client
How does it achieve fault tolerance?
- For correct operation, if the primary fails then
- The backups must agree on one backup to be the new primary
- All RMs must agree on which operations had been performed at the point when new primary takes over
- If a backup fails then the result just continue
- If a failed RM recovers then it must re-synchronise
Notes
- Surviving up to f crashes requires at least f+1 Replica Managers
- Cannot cope with Byzantine failures
- Has relatively large overheads
- Client may be able to submit read request to backup RMs
Option 2 - Active replication
- Request - Is sent by Front End to all Replica Managers
- Coordination - The multicast group delivers the request to all active RMs
- Execution - Every RM executes the request
- Agreement - None required with reliable multicast
- Response - Every RM sends response to FE